Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
105590001 |Substance|curl -u "test:test" 'http://localhost:8080/snowowl/snomedct/SNOMEDCT/concepts?ecl=%3C!138875005&limit=1&pretty'curl -u "test:test" http://localhost:8080/snowowl/snomedct/SNOMEDCT/concepts?prettycurl -v -u "test:test" http://localhost:8080/snowowl/snomedct/SNOMEDCT/import?type=snapshot\&createVersions=false \
-F file=@SnomedCT_InternationalRF2_PRODUCTION.zipgit clone https://github.com/b2ihealthcare/snow-owl.gitcd ./snow-owl/docker/composedocker compose up -dservices:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:8.11.1
container_name: elasticsearch
environment:
- "ES_JAVA_OPTS=-Xms6g -Xmx6g"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- es-data:/usr/share/elasticsearch/data
- ./config/elasticsearch/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- ./config/elasticsearch/synonym.txt:/usr/share/elasticsearch/config/analysis/synonym.txt
healthcheck:
test: curl --fail http://localhost:9200/_cluster/health?wait_for_status=green || exit 1
interval: 1s
timeout: 1s
retries: 60
ports:
- "127.0.0.1:9200:9200"
restart: unless-stopped
snowowl:
image: b2ihealthcare/snow-owl-oss:latest
container_name: snowowl
environment:
- "SO_JAVA_OPTS=-Xms6g -Xmx6g"
- "ELASTICSEARCH_URL=http://elasticsearch:9200"
depends_on:
elasticsearch:
condition: service_healthy
volumes:
- ./config/snowowl/snowowl.yml:/etc/snowowl/snowowl.yml
- ./config/snowowl/users:/etc/snowowl/users # default username and password: test - test
- es-data:/var/lib/snowowl/resources/indexes
ports:
- "8080:8080"
restart: unless-stopped
volumes:
es-data:
driver: local- "ES_JAVA_OPTS=-Xms2g -Xmx2g"- "SO_JAVA_OPTS=-Xms2g -Xmx2g"curl http://localhost:8080/snowowl/info?pretty{
"version": "<version number>",
"description": "You Know, for Terminologies",
"repositories": {
"items": [ {
"id": "snomed",
"health": "GREEN",
"diagnosis": "",
"indices" : [ {
"index": "snomed-relationship",
"status": "GREEN"
}, {
"index": "snomed-commit",
"status": "GREEN"
}, ...
} ]
}
}{
"items": [ {
"id": "105590001",
"released": true,
"active": true,
"effectiveTime": "20020131",
"moduleId": "900000000000207008",
"iconId": "substance",
"score": 0.0,
"memberOf": [ "723560006", "733073007", "900000000000497000" ],
"activeMemberOf": [ "723560006", "733073007", "900000000000497000" ],
"definitionStatus": {
"id": "900000000000074008"
},
"subclassDefinitionStatus": "NON_DISJOINT_SUBCLASSES",
"ancestorIds": [ "-1" ],
"parentIds": [ "138875005" ],
"statedAncestorIds": [ "-1" ],
"statedParentIds": [ "138875005" ],
"definitionStatusId": "900000000000074008"
} ],
"searchAfter": "AoEpMTA1NTkwMDAx",
"limit": 1,
"total": 19
}{
"items": [ ],
"limit": 50,
"total": 0
}< HTTP/1.1 201 Created
< Location: http://localhost:8080/snowowl/snomedct/SNOMEDCT/import/107f6efa69886bfdd73db5586dcf0e15f738efedcurl -u "test:test" http://localhost:8080/snowowl/snomedct/SNOMEDCT/import/107f6efa69886bfdd73db5586dcf0e15f738efed?pretty{
"id": "107f6efa69886bfdd73db5586dcf0e15f738efed",
"status": "RUNNING"
}{
"id": "107f6efa69886bfdd73db5586dcf0e15f738efed",
"status": "FINISHED",
"response": {
"visitedComponents": [ ... ],
"defects": [ ],
"success": true
}
}(Pro feature)
{
"id": "138875005",
"released": true,
"active": true,
"effectiveTime": "20020131",
"moduleId": "900000000000207008",
"iconId": "snomed_rt_ctv3",
"score": 0.0,
"memberOf": [ "900000000000497000" ],
"activeMemberOf": [ "900000000000497000" ],
"definitionStatus": {
"id": "900000000000074008"
},
"subclassDefinitionStatus": "NON_DISJOINT_SUBCLASSES",
"pt": {
"id": "220309016",
"term": "SNOMED CT Concept",
"concept": {
"id": "138875005"
},
"type": {
"id": "900000000000013009"
},
"typeId": "900000000000013009",
"conceptId": "138875005",
"acceptability": {
"900000000000509007": "PREFERRED",
"900000000000508004": "PREFERRED"
}
},
"ancestorIds": [ ],
"parentIds": [ "-1" ],
"statedAncestorIds": [ ],
"statedParentIds": [ "-1" ],
"definitionStatusId": "900000000000074008"
}

curl -u "test:test" 'http://localhost:8080/snowowl/snomedct/SNOMEDCT/concepts?term=M%C3%A9niere%27s%20disease&expand=pt()&pretty'export SO_JAVA_OPTS="$SO_JAVA_OPTS -Djava.io.tmpdir=/path/to/temp/dir"
./bin/startup./bin/shutdownsysctl -w vm.max_map_count=262144(Pro feature)
POST /codesystems
{
"id": "ICD10SE",
"url": "http://hl7.org/fhir/sid/icd-10-se",
"title": "ICD-10-SE",
"language": "se",
"description": "# Internationell statistisk klassifikation av sjukdomar och relaterade hälsoproblem (ICD-10-SE)",
"status": "active",
"owner": "ownerUserId",
"copyright": "",
"contact": "https://www.socialstyrelsen.se/statistik-och-data/klassifikationer-och-koder/kodtextfiler/",
"oid": "1.2.752.116.1.1.1",
"toolingId": "icd10",
"settings": {
"publisher": "Socialstyrelsen",
"isPublic": true
}
}POST /icd10/ICD10SE/classes/import -F "file=@ICD-10-SE_2024_generated.xml"POST /versions
{
"resource": "codesystems/ICD10SE",
"version": "2024-01-01",
"description": "2024-01-01 release",
"effectiveTime": "2024-01-01"
}(Pro feature)
POST /codesystems
{
"id": "LOINC",
"url": "http://hl7.org/fhir/sid/loinc",
"title": "LOINC",
"language": "en",
"description": "LOINC is a freely available international standard for tests, measurements, and observations",
"status": "active",
"copyright": "This material contains content from LOINC (http://loinc.org). LOINC is copyright ©1995-2023, Regenstrief Institute, Inc. and the Logical Observation Identifiers Names and Codes (LOINC) Committee and is available at no cost under the license at http://loinc.org/license. LOINC® is a registered United States trademark of Regenstrief Institute, Inc.",
"owner": "ownerUserId",
"contact": "https://loinc.org/",
"oid": "2.16.840.1.113883.6.1",
"toolingId": "loinc",
"settings": {
"publisher": "Regenstrief Institute, Inc.",
}
}POST /loinc/LOINC/import -F "file=@Loinc_2.77.zip"POST /versions
{
"resource": "codesystems/LOINC",
"version": "2.77",
"description": "LOINC 2.77 2024-02-27 release",
"effectiveTime": "2024-02-27"
}(Pro feature)
POST /codesystems
{
"id": "icf",
"url": "http://klassifikationer.socialstyrelsen.se/icf",
"title": "ICF",
"language": "se",
"description": "# Internationell klassifikation av funktionstillstånd, funktionshinder och hälsa",
"status": "active",
"contact": "[email protected] - Avdelningen för register och statistik, Enheten för klassifikationer och terminologi",
"owner": "ownerUserId",
"oid": "1.2.752.116.1.1.3",
"toolingId": "lcs",
"settings": {
"publisher": "Socialstyrelsen",
"isPublic": true
}
}POST /lcs/icf/import?idColumn=Kod&ptColumn=Titel&synonymColumns=Beskrivning&synonymColumns=Alternativ%20titel&parentColumn=Överordnad%20kod&locale=se -F "[email protected]"POST /versions
{
"resource": "codesystems/icf",
"version": "2024-01-01",
"description": "2024-01-01 release",
"effectiveTime": "2024-01-01"
}./snow-owl/docker):[root@host]# diff /opt/snow-owl/docker/ /opt/new-snow-owl-release/snow-owl/docker/
Common subdirectories: /opt/snow-owl/docker/configs and /opt/new-snow-owl-release/snow-owl/docker/configs
diff /opt/snow-owl/docker/.env /opt/new-snow-owl-release/snow-owl/docker/.env
10c10
< ELASTICSEARCH_VERSION=7.16.3
---
> ELASTICSEARCH_VERSION=7.17.1
24c24
< SNOWOWL_VERSION=8.1.0
---
> SNOWOWL_VERSION=8.1.1
docker compose pull
docker compose up -drepository:
index:
socketTimeout: 60000
clusterUrl: https://my-es-cluster.elastic-cloud.com:9243
clusterUsername: my-es-cluster-user
clusterPassword: my-es-cluster-pwdPOST /codesystems
{
"id": "kva-kirurgiska",
"url": "http://klassifikationer.socialstyrelsen.se/kva-kirurgiska",
"title": "KVÅ – kirurgiska åtgärder (KKÅ)",
"language": "se",
"description": "# Klassifikation av kirurgiska åtgärder",
"status": "active",
"owner": "ownerUserId",
"copyright": "",
"contact": "[email protected] - Avdelningen för register och statistik, Enheten för klassifikationer och terminologi",
"oid": "1.2.752.116.1.3.2.3.6",
"toolingId": "lcs",
"settings": {
"publisher": "Socialstyrelsen",
"isPublic": true
}
}POST /lcs/kva-kirurgiska/import?idColumn=Kod&ptColumn=Titel&synonymColumns=Förkortning(ar)&synonymColumns=Beskrivning&parentColumn=Överordnad%20kod&locale=se -F "[email protected]"curl -u "test:test" http://localhost:8080/snowowl/codesystems?pretty{
"items" : [ ],
"limit" : 0,
"total" : 0
}curl -X POST \
-u "test:test" \
-H "Content-type: application/json" \
http://localhost:8080/snowowl/codesystems \
-d '{
"id": "SNOMEDCT",
"url": "http://snomed.info/sct/900000000000207008",
"title": "SNOMED CT International Edition",
"description": "SNOMED CT International Edition",
"status": "active",
"copyright": "(C) 2025 International Health Terminology Standards Development Organisation 2002-2023. All rights reserved.",
"contact": "https://snomed.org",
"oid": "2.16.840.1.113883.6.96",
"toolingId": "snomed",
"settings": {
"moduleIds": [
"900000000000207008",
"900000000000012004"
],
"locales": [
"en-x-900000000000508004",
"en-x-900000000000509007"
],
"languages": [
{
"languageTag": "en",
"languageRefSetIds": [
"900000000000509007",
"900000000000508004"
]
},
{
"languageTag": "en-us",
"languageRefSetIds": [
"900000000000509007"
]
},
{
"languageTag": "en-gb",
"languageRefSetIds": [
"900000000000508004"
]
}
],
"publisher": "SNOMED International",
"namespace": "INT",
"namespaceConceptId": "373872000",
"maintainerType": "SNOMED_INTERNATIONAL"
}
}'curl -u "test:test" http://localhost:8080/snowowl/codesystems/SNOMEDCT?pretty{
"id": "SNOMEDCT",
"url": "http://snomed.info/sct/900000000000207008",
"title": "SNOMED CT International Edition",
"language": "en",
...
"branchPath": "MAIN/SNOMEDCT",
...
}{
"items": [ {
"id": "13445001",
"released": true,
"active": true,
"effectiveTime": "20020131",
"moduleId": "900000000000207008",
"iconId": "disorder",
"score": 3.9305625,
"memberOf": [ "447562003", "733073007", "900000000000497000" ],
"activeMemberOf": [ "447562003", "733073007", "900000000000497000" ],
"definitionStatus": {
"id": "900000000000074008"
},
"subclassDefinitionStatus": "NON_DISJOINT_SUBCLASSES",
"pt": {
"id": "178783019",
"term" : "Ménière's disease",
"concept": {
"id": "13445001"
},
"type": {
"id": "900000000000013009"
},
"typeId": "900000000000013009",
"conceptId": "13445001",
"acceptability": {
"900000000000509007": "PREFERRED",
"900000000000508004": "PREFERRED"
}
},
"ancestorIds": [ "-1", "20425006", ..., "1279550006" ],
"parentIds": [ "50438001" ],
"statedAncestorIds": [ "-1", "64572001", "138875005", "404684003" ],
"statedParentIds": [ "50438001" ],
"definitionStatusId": "900000000000074008"
}, {
...
} ],
"searchAfter": "AoIFQAd5LmITGo8wMTA4OTA5MTAwMDExOTEwNQ==",
"limit": 50,
"total": 27
}.
└── analysis
└── synonym.txtPOST /versions
{
"resource": "codesystems/kva-kirurgiska",
"version": "2024-01-01",
"description": "2024-01-01 release",
"effectiveTime": "2024-01-01"
}POST /codesystems
{
"id": "kva-medicinska",
"url": "http://klassifikationer.socialstyrelsen.se/kva-medicinska",
"title": "KVÅ – medicinska åtgärder (KMÅ)",
"language": "se",
"description": "# Klassifikation av medicinska åtgärder",
"status": "active",
"owner": "ownerUserId",
"copyright": "",
"contact": "[email protected] - Avdelningen för register och statistik, Enheten för klassifikationer och terminologi",
"oid": "1.2.752.116.1.3.2.3.5",
"toolingId": "lcs",
"settings": {
"publisher": "Socialstyrelsen",
"isPublic": true
}
}POST /lcs/kva-medicinska/import?idColumn=Kod&ptColumn=Titel&synonymColumns=Beskrivning&parentColumn=Överordnad%20kod&locale=se -F "[email protected]"POST /versions
{
"resource": "codesystems/kva-medicinska",
"version": "2024-01-01",
"description": "2024-01-01 release",
"effectiveTime": "2024-01-01"
}sudo swapoff -a# sysctl settings, to be added to /etc/sysctl.conf or equivalent
vm.swappiness = 1
vm.max_map_count = 262144tar --extract \
--gzip \
--verbose \
--same-owner \
--preserve-permissions \
--file=/path/to/snow-owl-linux-x86_64.tar.gz \
--directory=/opt/repository:
index:
clusterUrl: http://your.es.cluster:9200 # the ES cluster URL
clusterUsername: snowowl # Optional username to connect to a protected ES cluster
clusterPassword: snowowl_password # Optional password to connect to a protected ES clusterpath:
data: /var/data/snowowl# Set the minimum and maximum heap size to 12 GB.
SO_JAVA_OPTS="-Xms12g -Xmx12g" ./bin/startup./bin/startupnohup ./bin/startup > /dev/null &ps -p 1sudo chkconfig --add snowowlsudo -i service snowowl start
sudo -i service snowowl stopsudo /bin/systemctl daemon-reload
sudo /bin/systemctl enable snowowl.servicesudo systemctl start snowowl.service
sudo systemctl stop snowowl.servicesnowowl:
image: b2ihealthcare/snow-owl-<variant>:<version>
...
volumes:
- ./config/snowowl/snowowl.yml:/etc/snowowl/snowowl.yml
- ./config/snowowl/users:/etc/snowowl/users
- ${SNOWOWL_DATA_FOLDER}:/var/lib/snowowl
- ${SNOWOWL_LOG_FOLDER}:/var/log/snowowl
+ - /path/to/folder/with/fast/performance:/usr/share/snowowl/work
ports:
..../init-certificate.sh -d snow-owl.example.comchmod -R 1000:0 ./snow-owl/docker ./snow-owl/logs ./snow-owl/resourcescat docker_login.txt | docker login -u <username> --password-stdin https://docker.b2ihealthcare.comdocker compose pulldocker compose up -dcurl https://snow-owl.example.com/snowowl/infocurl http://hostname:8080/snowowl/infotar --extract \
--gzip \
--verbose \
--same-owner \
--preserve-permissions \
--file=snow-owl-resources.tar.gz \
--directory=/opt/snow-owl/resources/
chown -R 1000:0 /opt/snow-owl/resourcesSO_PATH_CONF=/path/to/my/config ./bin/startuppath:
data: /var/lib/snowowlpath.data: /var/lib/snowowlrepository.host: ${HOSTNAME}
repository.port: ${SO_REPOSITORY_PORT}...
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<fieldName>timestamp</fieldName>
<timeZone>UTC</timeZone>
</timestamp>
<loggerName>
<fieldName>logger</fieldName>
</loggerName>
<logLevel>
<fieldName>level</fieldName>
</logLevel>
<threadName>
<fieldName>thread</fieldName>
</threadName>
<nestedField>
<fieldName>mdc</fieldName>
<providers>
<mdc />
</providers>
</nestedField>
<stackTrace>
<fieldName>stackTrace</fieldName>
<throwableConverter class="net.logstash.logback.stacktrace.ShortenedThrowableConverter">
<maxDepthPerThrowable>200</maxDepthPerThrowable>
<maxLength>14000</maxLength>
<rootCauseFirst>true</rootCauseFirst>
</throwableConverter>
</stackTrace>
<message />
<throwableClassName>
<fieldName>exceptionClass</fieldName>
</throwableClassName>
</providers>
</encoder>
</appender>
...POST /compare
{
"baseBranch": "MAIN",
"compareBranch": "MAIN/a",
"limit": 100
}Status: 200 OK
{
"baseBranch": "MAIN",
"compareBranch": "MAIN/a",
"compareHeadTimestamp": 1567282434400,
"newComponents": [],
"changedComponents": ["138875005"],
"deletedComponents": [],
"totalNew": 0,
"totalChanged": 1,
"totalDeleted": 0
}GET /snomedct/MAIN@1567282434400/concepts/138875005Status: 200 OK
{
"id": "138875005",
...
}GET /snomedct/MAIN/concepts/138875005Status: 200 OK
{
"id": "138875005",
...
}GET /snomedct/MAIN/a^/concepts/138875005Status: 200 OK
{
"id": "138875005",
...
}POST /members/:id/actions
{
"commitComment": "Sync member's target reference set",
"action": "sync"
}PUT /:path/refsets/:id/members{
"commitComment": "Updating members of my simple type reference set",
"requests": [
{
"action": "create|update|delete|sync",
"action-specific-props": ...
}
]
}export:SNOMEDCT-US/2019-03-01 - export the 2019-03-01 US Extension release


BACKUP_FOLDER=/mnt/external_folder
NUMBER_OF_DAILY_BACKUPS_TO_KEEP=10
CRON_DAYS=Tue-Sat
CRON_HOURS=2
CRON_MINUTES=0root@host:/# docker exec -it backup bash
root@ad36cfb0448c:/# /backup/backup.sh -l my-backup-labelsnow-owl/
├── backup
├── docker
│ ├── configs
│ │ ├── cert
│ │ │ ├── conf.d
│ │ │ ├── docker-compose-cert.yml
│ │ │ ├── docker-compose.yml
│ │ │ ├── init-certificate.sh
│ │ │ └── nginx.conf
│ │ ├── elasticsearch
│ │ │ ├── elasticsearch.yml
│ │ │ └── synonym.txt
│ │ ├── ldap-bootstrap
│ │ │ ├── 100_groups.ldif
│ │ │ └── 200_users.ldif
│ │ ├── nginx
│ │ │ ├── conf.d
│ │ │ │ └── snowowl.conf
│ │ │ └── nginx.conf
│ │ └── snowowl
│ │ ├── snowowl.yml
│ │ └── users
│ ├── docker-compose.yml
│ ├── docker_login.txt
│ └── .env
├── ldap
├── logs
└── resources
├── attachments
└── indexes[root@host docker]# docker compose ps -a[root@host ~]# docker compose --file /opt/snow-owl/docker/docker-compose.yml ps -aGET /branches/:pathStatus: 200 OK
{
"name": "MAIN",
"baseTimestamp": 1431957421204,
"headTimestamp": 1431957421204,
"deleted": false,
"path": "MAIN",
"state": "UP_TO_DATE"
}GET /branchesStatus: 200 OK
{
"items": [
{
"name": "MAIN",
"baseTimestamp": 1431957421204,
"headTimestamp": 1431957421204,
"deleted": false,
"path": "MAIN",
"state": "UP_TO_DATE"
}
]
}POST /branches{
"parent" : "MAIN",
"name" : "branchName",
"metadata": {}
}Status: 201 Created
Location: http://localhost:8080/snowowl/snomedct/branches/MAIN/branchNameDELETE /branches/:pathStatus: 204 No contentPOST /merges{
"source" : "MAIN/branchName",
"target" : "MAIN"
}Status: 202 Accepted
Location: http://localhost:8080/snowowl/snomedct/merges/2f4d3b5b-3020-4e8e-b046-b8266967d7dcPOST /merges{
"source" : "MAIN",
"target" : "MAIN/branchName"
}Status: 202 Accepted
Location: http://localhost:8080/snowowl/snomedct/merges/c82c443d-f3f4-4409-9cdb-a744da336936GET /merges/c82c443d-f3f4-4409-9cdb-a744da336936{
"id": "c82c443d-f3f4-4409-9cdb-a744da336936",
"source": "MAIN",
"target": "MAIN/branchName",
"status": "COMPLETED",
"scheduledDate": "2016-02-29T13:52:45Z",
"startDate": "2016-02-29T13:52:45Z",
"endDate": "2016-02-29T13:53:06Z"
}DELETE /merges/c82c443d-f3f4-4409-9cdb-a744da336936Status: 204 No content[root@host]# pwd
/opt/snow-owl/docker/configs/cert
[root@host]# chmod +x init-certificate.sh
[root@host]# ./init-certificate.sh -h
DESCRIPTION:
Get certificate for the specified domain name using Let's Encrypt and certbot
OPTIONS:
-h
Show this help
-d domain
Define the domain name to get the certificate for
-e email (optional)
The email address to use for the certificate registration
EXAMPLES:
./init-certificate.sh -d mywebsite.com -e [email protected]
./init-certificate.sh -d example.com
./init-certificate.sh -d snow-owl.b2ihealthcare.com -e [email protected] nginx:
image: nginx:stable
container_name: nginx
volumes:
- ./configs/nginx/conf.d/:/etc/nginx/conf.d/
- ./configs/nginx/nginx.conf:/etc/nginx/nginx.conf
- ${CERT_FOLDER}/conf:/etc/letsencrypt
- ${CERT_FOLDER}/www:/var/www/certbot
depends_on:
- snowowl
ports:
- "80:80"
- "443:443"
# Reload nginx config every 6 hours and restart
command: "/bin/sh -c 'while :; do sleep 6h & wait $${!}; nginx -s reload; done & nginx -g \"daemon off;\"'"
restart: unless-stopped
certbot:
image: certbot/certbot:latest
container_name: certbot
volumes:
- ${CERT_FOLDER}/conf:/etc/letsencrypt
- ${CERT_FOLDER}/www:/var/www/certbot
# Check for SSL cert renewal every 12 hours
entrypoint: "/bin/sh -c 'trap exit TERM; while :; do certbot renew; sleep 12h & wait $${!}; done;'"
restart: unless-stoppedSNOMEDCT-UK-CL, SNOMEDCT-UK-DR - United Kingdom Clinical and Drug Extensions, respectively
root@host:/# docker exec -it backup bash
root@ad36cfb0448c:/# /backup/restore.shdocker compose stop snowowl elasticsearch ldapmv -t /tmp ./snow-owl/resources/indexes/nodesdocker compose start elasticsearchroot@ad36cfb0448c:/# /backup/restore.sh
################################
Snow Owl restore script STARTED.
#### Verify Elasticsearch snapshot repository ####
Checking existence of repository 'snowowl-snapshots' ...
Repository with name 'snowowl-snapshots' is present, verifying repository state ...
Repository 'snowowl-snapshots' is functional
#### Select backup to restore ####
Found 10 available backups under '/backup'
Please select the backup to restore by choosing the right number in the menu below (hit Enter when the selection was made)
1) snowowl-daily-20220323030001
2) snowowl-daily-20220324030001
3) snowowl-daily-20220325030002
4) snowowl-daily-20220326030002
5) snowowl-daily-20220329030001
6) snowowl-daily-20220330030001
7) snowowl-daily-20220331030002
8) snowowl-daily-20220401030002
9) snowowl-daily-20220402030001
10) snowowl-daily-20220405030002
#?
root@ad36cfb0448c:/# exit
root@host:/# docker compose up -dsudo su # Become `root`
ulimit -n 65536 # Change the max number of open files
su snowowl # Become the `snowowl` user in order to start Snow Owlsnowowl - nofile 65536[Service]
LimitMEMLOCK=infinitysudo systemctl daemon-reloadidentity:
providers:
- ldap:
uri: <ldap_uri>
bindDn: cn=admin,dc=snowowl,dc=b2international,dc=com
bindDnPassword: <adminpwd>
baseDn: dc=snowowl,dc=b2international,dc=com
roleBaseDn: {baseDn}
userFilter: (objectClass={userObjectClass})
roleFilter: (objectClass={roleObjectClass})
userObjectClass: inetOrgPerson
roleObjectClass: groupOfUniqueNames
userIdProperty: uid
permissionProperty: description
memberProperty: uniqueMember
usePool: falsewget https://github.com/b2ihealthcare/snow-owl/releases/download/<version>/snow-owl-oss-<version>.deb
wget https://github.com/b2ihealthcare/snow-owl/releases/download/<version>/snow-owl-oss-<version>.deb.sha512
shasum -a 512 -c snow-owl-oss-<version>.deb.sha512 # Compares the SHA of the downloaded Debian package and the published checksum, which should output `snow-owl-oss-<version>.deb: OK`.
sudo dpkg -i snow-owl-oss-<version>.deb














root@host:/# docker exec -it backup bash
root@ad36cfb0448c:/# /backup/restore.sh -l# session required pam_limits.sohtpasswd -nBC 10 my-new-username | head -n1 | sed 's/$2y/$2a/g' >> ./snow-owl/docker/configs/snowowl/usersdn: cn=John [email protected],dc=snowowl,dc=b2international,dc=com
objectClass: inetOrgPerson
objectClass: organizationalPerson
objectClass: person
objectClass: top
cn: John Doe
sn: Doe
uid: [email protected]
userPassword: <encrypted_password> dn: cn=Browser,dc=snowowl,dc=b2international,dc=com
objectClass: top
objectClass: groupOfUniqueNames
cn: Browser
description: browse:*
description: export:*
uniqueMember: cn=John [email protected],dc=snowowl,dc=b2international,dc=com wget https://github.com/b2ihealthcare/snow-owl/releases/download/<version>/snow-owl-oss-<version>.rpm
wget https://github.com/b2ihealthcare/snow-owl/releases/download/<version>/snow-owl-oss-<version>.rpm.sha512
shasum -a 512 -c snow-owl-oss-<version>.rpm.sha512 # Compares the SHA of the downloaded RPM and the published checksum, which should output `snow-owl-oss-<version>.rpm: OK`.
sudo rpm --install snow-owl-oss-<version>.rpmsudo chkconfig --add snowowlsudo -i service snowowl start
sudo -i service snowowl stopsudo /bin/systemctl daemon-reload
sudo /bin/systemctl enable snowowl.servicesudo systemctl start snowowl.service
sudo systemctl stop snowowl.servicecurl http://localhost:8080/snowowl/info{
"version": "<version_number>",
"description": "You Know, for Terminologies",
"repositories": {
"items": [
{
"id": "snomedStore",
"health": "GREEN"
}
]
}
}wget https://github.com/b2ihealthcare/snow-owl/releases/download/<version>/snow-owl-oss-<version>.zip
wget https://github.com/b2ihealthcare/snow-owl/releases/download/<version>/snow-owl-oss-<version>.zip.sha512
shasum -a 512 -c snowowl-oss-<version>.zip.sha512 # compares the SHA of the downloaded archive, should output: `snowowl-oss-<version>.zip: OK.`
unzip snowowl-oss-<version>.zip
cd snowowl-oss-<version>/ # This directory is known as `$SO_HOME`wget https://github.com/b2ihealthcare/snow-owl/releases/download/<version>/snow-owl-oss-<version>.tar.gz
wget https://github.com/b2ihealthcare/snow-owl/releases/download/<version>/snow-owl-oss-<version>.tar.gz.sha512
shasum -a 512 -c snowowl-oss-<version>.tar.gz.sha512 # compares the SHA of the downloaded archive, should output: `snowowl-oss-<version>.tar.gz: OK.`
tar -xzf snowowl-oss-<version>.tar.gz
cd snowowl-oss-<version>/ # This directory is known as `$SO_HOME`./bin/startupcurl http://localhost:8080/snowowl/info{
"version": "<version_number>",
"description": "You Know, for Terminologies",
"repositories": {
"items": [
{
"id": "snomedStore",
"health": "GREEN"
}
]
}
}nohup ./bin/startup > /dev/null &kill <pid>./bin/shutdownsudo update-rc.d snowowl defaults 95 10sudo -i service snowowl start
sudo -i service snowowl stopsudo /bin/systemctl daemon-reload
sudo /bin/systemctl enable snowowl.servicesudo systemctl start snowowl.service
sudo systemctl stop snowowl.servicecurl http://localhost:8080/snowowl/info{
"version": "<version_number>",
"description": "You Know, for Terminologies",
"repositories": {
"items": [
{
"id": "snomedStore",
"health": "GREEN"
}
]
}
}



YYYY-MM-DDTHH:MM:SSZyyyyMMddhttp://example.com/snowowl/snomedct/SNOMEDCT/concepts/123456789GET /snowowl/snomedct/SNOMEDCT/concepts?limit=50&expand=fsn(),descriptions(){
"items": [
{
"id": "100005",
"released": true,
...
"fsn": {
"id": "2709997016",
"term": "SNOMED RT Concept (special concept)",
...
},
"descriptions": {
"items": [
{
"id": "208187016",
"released": true,
...
},
],
"offset": 0,
"limit": 5,
"total": 5
}
},
...
],
"offset": 0,
"limit": 50,
"total": 421657
}// 400 Bad Request
{
"status" : "400",
"message" : "Invalid JSON representation",
"developerMessage" : "detailed information about the error for developers"
}// 400 Bad Request
{
"status" : "400",
"message" : "2 Validation errors",
"developerMessage" : "Input representation syntax or validation errors. Check input values.",
"violations" : ["violation_message_1", "violation_message_2"]
}// 409 Conflict
{
"status" : "409",
"message" : "Cannot merge source 'branch1' into target 'MAIN'."
}// 500 Internal Server Error
{
"status" : "500",
"message" : "Something went wrong during the processing of your request.",
"developerMessage" : "detailed information about the error for developers"
}GET /snomedct/MAIN/2021-01-31/SNOMEDCT-UK-CL/concepts
{
"items": [
{
"id": "100000000",
"released": true,
"active": false,
"effectiveTime": "20090731",
[...]GET /snomedct/SNOMEDCT-UK-CL/100/conceptsGET /snomedct/MAIN/2021-01-31/SNOMEDCT-UK-CL/100/conceptsGET /snomedct/MAIN/2019-07-31/SNOMEDCT-UK-CL/2020-08-05...MAIN/2021-01-31/SNOMEDCT-UK-CL/conceptsGET /snomedct/MAIN@1630504199999/conceptsGET /snomedct/MAIN/2019-07-31/SNOMEDCT-UK-CL/101^/concepts


textidmeta
Accept: application/fhir+json;fhirVersion=4.0.1GET /snowowl/fhir/CodeSystem/SNOMEDCT?_format=xml&_pretty=true
[Response headers]
Content-Type: application/fhir+xml
<CodeSystem xmlns="http://hl7.org/fhir">
<id value="SNOMEDCT"/>
<meta>
<lastUpdated value="2023-10-17T15:03:40.942Z"/>
</meta>
<language value="en"/>
<text>
<status value="empty"/>
<div xmlns="http://www.w3.org/1999/xhtml"></div>
</text>
<url value="http://snomed.info/sct/900000000000207008"/>
<name value="SNOMEDCT"/>
<title value="SNOMED CT International Edition"/>
<status value="active"/>
[...]GET /snowowl/fhir/CodeSystem/SNOMEDCT?_summary=text
[Response headers]
Content-Type: application/fhir+json
{
"resourceType": "CodeSystem",
"id": "SNOMEDCT",
"meta": {
"lastUpdated": "2023-10-17T15:03:40.942Z",
"tag": [{
"system": "http://terminology.hl7.org/CodeSystem/v3-ObservationValue",
"code": "SUBSETTED",
"display": "As requested, resource is not fully detailed."
}]
},
"text": {
"status": "empty",
"div": "<div xmlns=\"http://www.w3.org/1999/xhtml\"></div>"
},
"status": "active",
"content": "not-present"
}GET /snowowl/fhir/CodeSystem?_count=5
[Response headers]
Content-Type: application/fhir+json
{
"resourceType": "Bundle",
"id": "codesystems",
"meta": {
"lastUpdated": "2023-11-28T18:37:52.057338Z"
},
"type": "searchset",
"link": [{
"relation": "next",
"url": "https://<host>/snowowl/fhir/CodeSystem?_count=5&_after=AoIhMDg2dlE2dHd4YkRDNnZHWjUxNGYzWlplR2M="
}],
"total": 1676,
"entry": [
{
"fullUrl": "https://<host>/snowowl/fhir/CodeSystem/resource_1",
"resource": {
"resourceType": "CodeSystem",
"id": "resource_1",
"meta": {
"lastUpdated": "2023-10-19T13:21:52.216Z"
},
"name": "resource_1",
"title": "First resource",
...
}
},
...
]
}GET /snowowl/fhir/CodeSystem/SNOMEDCT/2021-01-31
[Response headers]
Content-Type: application/fhir+json
{
"resourceType": "CodeSystem",
"id": "SNOMEDCT/2021-01-31",
"meta": {
"lastUpdated": "2023-10-17T14:59:31.529Z"
},
"url": "http://snomed.info/sct/900000000000207008/version/20210131",
"version": "2021-01-31",
"name": "SNOMEDCT/2021-01-31",
"title": "SNOMED CT International Edition",
"status": "active",
"date": "2021-01-31T00:00:00Z",
"publisher": "SNOMED International",
"content": "not-present",
"count": 481509,
...
}GET /snowowl/fhir/CodeSystem/abc
[Response headers]
Content-Type: application/fhir+xml
<OperationOutcome>
<resourceType>OperationOutcome</resourceType>
<issue>
<severity>error</severity>
<code>not_found</code>
<diagnostics>
Code System with identifier 'abc' could not be found.
</diagnostics>
<details>
<text>Resource Id 'abc' does not exist</text>
<coding>
<code>msg_no_exist</code>
<system>http://hl7.org/fhir/operation-outcome</system>
<display>Resource Id 'abc' does not exist</display>
</coding>
</details>
<location>abc</location>
</issue>
</OperationOutcome>X-Owner -> sets the owner of the resource, for access control purposes in external systems (defaults to the author or the authenticated user if the former is not set)GET /snowowl/fhir/ConceptMap/69YWt6qc1ydgwARjh8XNw2
[Response headers]
Content-Type: application/fhir+json
{
"resourceType": "ConceptMap",
"id": "69YWt6qc1ydgwARjh8XNw2",
"meta": {
"lastUpdated": "2023-11-30T16:36:31.653Z"
},
"language": "en",
"text": {
"status": "empty",
"div": "<div xmlns=\"http://www.w3.org/1999/xhtml\"></div>"
},
"url": "https://b2ihealthcare.com/conceptmaps/example-concept-map",
"name": "69YWt6qc1ydgwARjh8XNw2",
"title": "Example Concept Map",
"status": "draft",
"description": "# Example Concept Map",
"group": [
{
"source": "http://snomed.info/sct/900000000000207008|2023-10-01",
"target": "https://b2ihealthcare.com/codesystems/example-lcs-1|v1",
"element": [
{
"code": "103015000",
"display": "Thoracic nerve root pain",
"target": [
{
"code": "C00",
"display": "Root concept",
"relationship": "equivalent"
}
]
}
]
}
]
}PUT /snowowl/fhir/ConceptMap/69YWt6qc1ydgwARjh8XNw2
[Request headers]
X-Author: [email protected]
Content-Type: application/fhir+json
[Request body]
{
"resourceType": "ConceptMap",
"id": "69YWt6qc1ydgwARjh8XNw2",
"meta": {
"lastUpdated": "2023-11-30T16:36:31.653Z"
},
"language": "en",
"text": {
"status": "empty",
"div": "<div xmlns=\"http://www.w3.org/1999/xhtml\"></div>"
},
"url": "https://b2ihealthcare.com/conceptmaps/example-concept-map",
"name": "69YWt6qc1ydgwARjh8XNw2",
"title": "Example Concept Map",
"status": "draft",
"description": "# Example Concept Map",
"group": [
{
"source": "http://snomed.info/sct/900000000000207008|2023-10-01",
"target": "https://b2ihealthcare.com/codesystems/example-lcs-1|v1",
"element": [
{
"code": "103015000",
"display": "Thoracic nerve root pain",
"target": [
{
"code": "C00",
"display": "Root concept",
"relationship": "equivalent"
}
]
},
// Added mapping
{
"code": "102506008",
"display": "Well child (finding)",
"target": [
{
"code": "C00-1",
"display": "Child concept",
"relationship": "equivalent"
}
]
}
]
}
]
}DELETE /snowowl/fhir/ConceptMap/69YWt6qc1ydgwARjh8XNw2
[Request headers]
X-Author: [email protected]
[Response]
204 No ContentPOST /snowowl/fhir/ConceptMap
[Request headers]
X-Effective-Date: 2023-11-29
X-Author: [email protected]
X-Owner: [email protected]
X-Owner-Profile-Name: Resource Owner
X-Bundle-Id: parent-bundle-id
Content-Type: application/fhir+json
[Request body]
{
"resourceType": "ConceptMap",
// "id": "..." is not used by the server
"text": {
"status": "empty",
"div": "<div xmlns=\"http://www.w3.org/1999/xhtml\"></div>"
},
"url": "https://b2ihealthcare.com/conceptmaps/example-concept-map-2",
"title": "Example Concept Map",
"status": "draft",
"group": [
{
"source": "http://snomed.info/sct/900000000000207008|2023-10-01",
"target": "https://b2ihealthcare.com/codesystems/example-lcs-1|v1",
"element": [
{
"code": "103015000",
"display": "Thoracic nerve root pain (finding)",
"target": [
{
"code": "C00",
"display": "Root concept",
"relationship": "equivalent"
}
]
}
]
}
]
}
[Response]
201 Created
[Response headers]
Location: http://<host>/snowowl/fhir/ConceptMap/cndkDE31kfeXw8GET /snowowl/fhir/ConceptMap?status=active&_summary=count
[Response headers]
Content-Type: application/fhir+json
{
"resourceType": "Bundle",
"id": "conceptmaps",
"meta": {
"lastUpdated": "2023-11-30T16:52:08.443803Z"
},
"type": "searchset",
"total": 22
}GET /snowowl/fhir/ConceptMap/cndkDE31kfeXw8/$translate?system=http://snomed.info/sct/900000000000207008&code=103015000
[Query parametes (repeated for clarity)]
system: http://snomed.info/sct/900000000000207008
code: 103015000
[Response headers]
Content-Type: application/fhir+json
{
"resourceType": "Parameters",
"parameter": [
{
"name": "result",
"valueBoolean": true
},
{
"name": "message",
"valueString": "1 member(s) from concept map: cndkDE31kfeXw8"
},
{
"name": "match",
"part": [
{
"name": "relationship",
"valueCode": "equivalent"
},
{
"name": "concept",
"valueCoding": {
"system": "codesystems/example-lcs-1",
"code": "C00",
"display": "Root concept"
}
},
{
"name": "originMap",
"valueUri": "cndkDE31kfeXw8"
}
]
}
]
}http://snomed.info/sct/900000000000207008?fhir_vs=refset/733073007 - all concepts of the International Edition that are members of the reference set 733073007|OWL axiom reference set|X-Owner -> sets the owner of the resource, for access control purposes in external systems (defaults to the author or the authenticated user if the former is not set)GET /snowowl/fhir/ValueSet/xJn9vXKMrkU9F
[Response headers]
Content-Type: application/fhir+json
{
"resourceType": "ValueSet",
"id": "xJn9vXKMrkU9F",
"meta": {
"lastUpdated": "2023-11-30T10:22:59.716Z"
},
"text": {
"status": "empty",
"div": "<div xmlns=\"http://www.w3.org/1999/xhtml\"></div>"
},
"url": "https://b2ihealthcare.com/valuesets/xJn9vXKMrkU9F",
"name": "xJn9vXKMrkU9F",
"title": "Example Value Set",
"status": "draft",
"compose": {
"include": [
{
"system": "http://snomed.info/sct/900000000000207008",
"version": "2023-10-01",
"filter": [
{
"property": "expression",
"op": "=",
"value": "<<448771007|Canis lupus subspecies familiaris (organism)|"
}
]
}
]
}
}PUT /snowowl/fhir/ValueSet/xJn9vXKMrkU9F
[Request headers]
X-Author: [email protected]
Content-Type: application/fhir+json
[Request body]
{
"resourceType": "ValueSet",
"id": "xJn9vXKMrkU9F",
"text": {
"status": "empty",
"div": "<div xmlns=\"http://www.w3.org/1999/xhtml\"></div>"
},
"url": "https://b2ihealthcare.com/valuesets/xJn9vXKMrkU9F",
"name": "xJn9vXKMrkU9F",
"title": "Example Value Set",
"status": "draft",
"compose": {
"include": [
{
"system": "http://snomed.info/sct/900000000000207008",
"version": "2023-10-01",
"filter": [
{
"property": "expression",
"op": "=",
"value": "<<448771007|Canis lupus subspecies familiaris (organism)|"
}
]
},
// Added inclusion
{
"system": "http://snomed.info/sct/900000000000207008",
"version": "2023-10-01",
"filter": [
{
"property": "expression",
"op": "=",
"value": "<<448169003|Felis catus (organism)|"
}
]
}
]
}
}DELETE /snowowl/fhir/ValueSet/xJn9vXKMrkU9F
[Request headers]
X-Author: [email protected]
[Response]
204 No ContentPOST /snowowl/fhir/ValueSet
[Request headers]
X-Effective-Date: 2023-11-29
X-Author: [email protected]
X-Owner: [email protected]
X-Owner-Profile-Name: Resource Owner
X-Bundle-Id: parent-bundle-id
Content-Type: application/fhir+json
[Request body]
{
"resourceType": "ValueSet",
// "id": "..." is not used by the server
"text": {
"status": "empty",
"div": "<div xmlns=\"http://www.w3.org/1999/xhtml\"></div>"
},
"url": "https://b2ihealthcare.com/valuesets/basic-dose-forms",
"title": "Basic dose forms",
"version": "v1",
"status": "active",
"compose": {
"include": [ {
"system": "http://snomed.info/sct/900000000000207008",
"version": "2021-01-31",
"filter": [ {
"property": "expression",
"op": "=",
"value": "<736478001|Basic dose form (basic dose form)|"
} ]
} ]
}
}
[Response]
201 Created
[Response headers]
Location: http://<host>/snowowl/fhir/ValueSet/vmfRt532iSGET /snowowl/fhir/ValueSet?status=draft&_summary=count
[Response headers]
Content-Type: application/fhir+json
{
"resourceType": "Bundle",
"id": "valuesets",
"meta": {
"lastUpdated": "2023-11-30T14:29:15.724489Z"
},
"type": "searchset",
"total": 188
}GET /snowowl/fhir/ValueSet/$expand?url=https://b2ihealthcare.com/valuesets/basic-dose-forms&count=3
[Query parameters (repeated for clarity)]
url: https://b2ihealthcare.com/valuesets/basic-dose-forms
count: 3
[Response headers]
Content-Type: application/fhir+json
{
"resourceType": "ValueSet",
"id": "vmfRt532iS",
"meta": {
"lastUpdated": "2023-11-30T10:22:59.716Z"
},
"url": "https://b2ihealthcare.com/valuesets/basic-dose-forms",
"name": "vmfRt532iS",
"title": "Basic dose forms",
"status": "active",
"compose": {
"include": [
{
"system": "http://snomed.info/sct/900000000000207008",
"version": "2021-01-31",
"filter": [
{
"property": "expression",
"op": "=",
"value": "<736478001|Basic dose form (basic dose form)|"
}
]
}
]
},
// This element does not appear when the VS is requested in a read interaction
"expansion": {
"identifier": "vmfRt532iS",
// Link to the next page in the expansion (includes the "_after" parameter)
"next": "https://uat.snowray.app/snowowl/fhir/ValueSet/$expand?url=https://b2ihealthcare.com/valuesets/basic-dose-forms&displayLanguage=en-US;q=0.8,en-GB;q=0.6,en;q=0.4&count=3&after=AoEqMTIzMDIxNzAwNw==",
"timestamp": "2023-11-30T13:07:32.254Z",
"total": 71,
// The number of results on a single page was limited to 3 by parameter "_count"
"contains": [
{
"system": "codesystems/SNOMEDCT/2021-01-31",
"code": "1230183009",
"display": "Dispersion (basic dose form)"
},
{
"system": "codesystems/SNOMEDCT/2021-01-31",
"code": "1230206006",
"display": "Compressed lozenge (basic dose form)"
},
{
"system": "codesystems/SNOMEDCT/2021-01-31",
"code": "1230217007",
"display": "Molded lozenge (basic dose form)"
}
]
}
}
GET /snowowl/fhir/ValueSet/$expand?url=https://b2ihealthcare.com/valuesets/basic-dose-forms&system=http://snomed.info/sct/900000000000207008&code=429885007
[Query parameters (repeated for clarity)]
url: https://b2ihealthcare.com/valuesets/basic-dose-forms
system: http://snomed.info/sct/900000000000207008
code: 429885007
[Response headers]
Content-Type: application/fhir+json
{
"resourceType": "Parameters",
"parameter": [
{
"name": "result",
"valueBoolean": true
},
{
"name": "message",
"valueString": "OK"
},
{
"name": "display",
"valueString": "Bar"
}
]
}SNOMED-CT/2020-01-31) and the resource is not listed among the selected resources, then only versions created until 2020-01-31 will be syndicated
...
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:${ELASTICSEARCH_VERSION}
container_name: elasticsearch
...
ports:
- - "127.0.0.1:9200:9200"
+ - "9200:9200"POST /_security/api_key
{
"name": "syndication-api-key",
"expiration": "30d",
"role_descriptors": {
"syndicate-role": {
"cluster": [
"monitor"
],
"indices": [
{
"names": [
"*"
],
"privileges": [
"read"
]
}
]
}
}
}{
"id" : "<token_id>",
"name" : "syndication-api-key",
"expiration" : 0,
"api_key" : "<api_key>",
"encoded" : "<encoded_api_key>"
}{
token: "<snow-owl-api-key>"
}PUT /codesystems/example_codesystem_id
{
"settings": {
"distributable": true
}
}...
http.port: 9200
...
reindex.remote.whitelist: ["upstream-elasticsearch-url.com:9200", "other-upstream-elasticsearch-url.com:9200"]<?xml version="1.0" encoding="UTF-8"?>
<feed xmlns="http://www.w3.org/2005/Atom">
<id>urn:uuid:ddce3cd6-2efe-3142-9cce-62e73d3031ca</id>
<title>Snow Owl® Terminology Server Syndication Feed</title>
...
<entry>
<id>valuesets/1234/V1.0</id>
...
<title>Valueset example</title>
<category term="BINARY" scheme="https://b2ihealthcare.com/snow-owl/syndication/binary/1.0.0" label="Binary index"/>
...
</entry>
</feed>{
// Response
}{
"resource": "SNOMED-CT-US",
"version": "SNOMED-CT/2021-01-31"
}{
"resource": "SNOMED-CT-US, SNOMED-CT"
"version": ""
}{
"resource": "VS"
"version": "SNOMED-CT/2020-07-31"
}{
"resource": "CM"
"version": "LOINC/v2.72, ICD-10/v2019"
}{
"items": [
{
"id": "SNOMED-CT/2022-01-31",
"version": "2022-01-31",
"description": "2022-01-31",
"effectiveTime": "2022-01-31",
"resource": "codesystems/SNOMED-CT"
},
{
"id": "SNOMED-CT/2022-07-31",
"version": "2022-07-31",
"description": "2022-07-31",
"effectiveTime": "2022-07-31",
"resource": "codesystems/SNOMED-CT"
}
]
"limit": 50,
"total": 2
}GET /snowowl/fhir/CodeSystem/SNOMEDCT-US?_pretty=true
[Response headers]
Content-Type: application/fhir+xml
<CodeSystem xmlns="http://hl7.org/fhir">
<id value="SNOMEDCT-US"/>
<meta>
<lastUpdated value="2023-10-18T01:52:16.04Z"/>
</meta>
<language value="en"/>
...
<url value="http://snomed.info/sct/731000124108"/>
...
<name value="SNOMEDCT-US"/>
<title value="SNOMED CT US Extension"/>
<status value="active"/>
<publisher value="NIH - National Library of Medicine"/>
...
<content value="not-present"/>
<count value="513765"/>
...GET /snowowl/fhir/CodeSystem/$lookup?system=http://snomed.info/sct/731000124108&code=138875005&_pretty=true
[Query parameters (repeated for clarity)]
system: http://snomed.info/sct/731000124108
code: 138875005
_pretty: true
[Response headers]
Content-Type: application/fhir+xml
<Parameters xmlns="http://hl7.org/fhir">
<parameter>
<name value="name"/>
<valueString value="SNOMEDCT-US"/>
</parameter>
<parameter>
<name value="display"/>
<valueString value="SNOMED CT Concept"/>
</parameter>
</Parameters>GET /snowowl/fhir/CodeSystem/SNOMEDCT-UK-CL/2023-08-02
[Response headers]
Content-Type: application/fhir+json
{
"resourceType": "CodeSystem",
"id": "SNOMEDCT-UK-CL/2023-08-02",
"meta": {
"lastUpdated": "2023-10-17T15:44:27.568Z"
},
"language": "en",
"text": {
"status": "empty",
"div": "<div xmlns=\"http://www.w3.org/1999/xhtml\"></div>"
},
"url": "http://snomed.info/sct/999000011000000103",
...
"name": "SNOMEDCT-UK-CL/2023-08-02",
"title": "SNOMED CT UK Clinical Extension",
"status": "active",
"date": "2023-08-02T00:00:00Z", // Versioned resources include the "date" property
"publisher": "NHS England",
"contact": [ {
"telecom": [ {
"system": "url",
"value": "https://www.england.nhs.uk/"
} ]
} ],
"description": "SNOMED CT UK Clinical Extension",
...
}PUT /snowowl/fhir/CodeSystem/example-lcs-1
[Request headers]
X-Effective-Date: 2023-11-29
X-Author: [email protected]
X-Owner: [email protected]
X-Owner-Profile-Name: Resource Owner
X-Bundle-Id: parent-bundle-id
Content-Type: application/fhir+json
[Request body]
{
"resourceType": "CodeSystem",
"id": "example-lcs-1",
"text": {
"status": "empty",
"div": "<div xmlns=\"http://www.w3.org/1999/xhtml\"></div>"
},
"url": "https://b2ihealthcare.com/codesystems/example-lcs-1",
"name": "example-lcs-1",
"version": "v1",
"title": "Example LCS",
"status": "draft",
"content": "complete",
"count": 2,
"concept": [
{
"code": "C00",
"display": "Parent concept"
},
{
"code": "C00-1",
"display": "Child concept",
"property": [ {
"code": "parent",
"valueCode": "C00"
} ]
}
]
}DELETE /snowowl/fhir/CodeSystem/example-lcs-1?force=true
[Request headers]
X-Author: [email protected]
[Response]
204 No ContentPOST /snowowl/fhir/CodeSystem
[Request headers]
X-Effective-Date: 2023-11-29
X-Author: [email protected]
X-Owner: [email protected]
X-Owner-Profile-Name: Resource Owner
X-Bundle-Id: parent-bundle-id
Content-Type: application/fhir+json
[Request body]
{
"resourceType": "CodeSystem",
// "id": "..." is not used by the server
"text": {
"status": "empty",
"div": "<div xmlns=\"http://www.w3.org/1999/xhtml\"></div>"
},
"url": "https://b2ihealthcare.com/codesystems/example-lcs-1",
"name": "example-lcs-1",
"version": "v1",
"title": "Example LCS",
"status": "active",
"content": "complete",
"count": 2,
"concept": [
{
"code": "C00",
"display": "Parent concept"
},
{
"code": "C00-1",
"display": "Child concept",
"property": [ {
"code": "parent",
"valueCode": "C00"
} ]
}
]
}
[Response]
201 Created
[Response headers]
Location: http://<host>/snowowl/fhir/CodeSystem/ExWn1g2gdIIQGET /snowowl/fhir/CodeSystem?_summary=count
[Response headers]
Content-Type: application/fhir+json
{
"resourceType": "Bundle",
"id": "codesystems",
"meta": {
"lastUpdated": "2023-11-29T16:15:36.187124Z"
},
"type": "searchset",
"total": 1685
}GET /snowowl/fhir/CodeSystem/$lookup?system=http://snomed.info/sct&code=128927009&property=inactive&property=http://snomed.info/id/260686004
[Query parameters (repeated for clarity)]
system: http://snomed.info/sct
code: 128927009
property: inactive
property: http://snomed.info/id/260686004
[Response headers]
Content-Type: application/fhir+json
{
"resourceType": "Parameters",
"parameter": [
{
"name": "name",
"valueString": "SNOMEDCT" // The code system name (resolved from the URL)
},
{
"name": "display",
"valueString": "Procedure by method" // The concept's display name
},
{
"name": "property",
"part": [
{
"name": "code",
"valueCode": "inactive"
},
{
"name": "value",
"valueBoolean": false // The value for the concept property "inactive"
},
{
"name": "description",
"valueString": "inactive"
}
]
},
{
"name": "property",
"part": [
{
"name": "code",
"valueCode": "260686004" // The SCTID of the attribute "Method"
},
{
"name": "value",
"valueCode": "129264002" // The SCTID of the destination concept, "Action"
}
]
}
]
}GET /snowowl/fhir/CodeSystem/SNOMEDCT/2021-07-31/$validate-code?code=128927009
[Response headers]
Content-Type: application/fhir+json
{
"resourceType": "Parameters",
"parameter": [
{
"name": "result",
"valueBoolean": true
}
]
}GET /snowowl/fhir/CodeSystem/$subsumes?codeA=409822003&codeB=112283007&system=http://snomed.info/sct/900000000000207008/version/20220228
[Query parameters (repeated for clarity)]
codeA: 409822003
codeB: 112283007
system: http://snomed.info/sct/900000000000207008/version/20220228
[Response headers]
Content-Type: application/fhir+json
{
"resourceType": "Parameters",
"parameter": [
{
"name": "outcome",
"valueCode": "subsumes"
}
]
}falsereferenceSet()preferredDescriptions()semanticTags()inactivationProperties()members()module()definitionStatus()pt() and fsn()descriptions()relationships()inboundRelationships()descendants() / statedDescendants()ancestors() / statedAncestors()environment_locationethnic_groupeventfindinggeographic_locationinactive_conceptintended_sitelife_stylelink_assertionlinkage_conceptmedicinal_productmedicinal_product_formmetadatamorphologic_abnormalitynamespace_conceptnavigational_conceptobservable_entityoccupationorganismowl_metadata_conceptpersonphysical_forcephysical_objectprocedureproductproduct_namequalifier_valueracial_grouprecord_artifactregime_therapyrelease_characteristicreligion_philosophyrolesituationsnomed_rt_ctv3social_conceptspecial_conceptspecimenstaging_scalestate_of_mattersubstancesuppliertransformationtumor_stagingunit_of_presentationancestorIdsYYYYmmdd{
"id": "138875005",
"released": true,
"active": true,
"effectiveTime": "20020131",
"moduleId": "900000000000207008",
"iconId": "snomed_rt_ctv3",
"definitionStatus": {
"id": "900000000000074008"
},
"subclassDefinitionStatus": "NON_DISJOINT_SUBCLASSES",
"ancestorIds": [],
"parentIds": [
"-1"
],
"statedAncestorIds": [],
"statedParentIds": [
"-1"
],
"definitionStatusId": "900000000000074008"
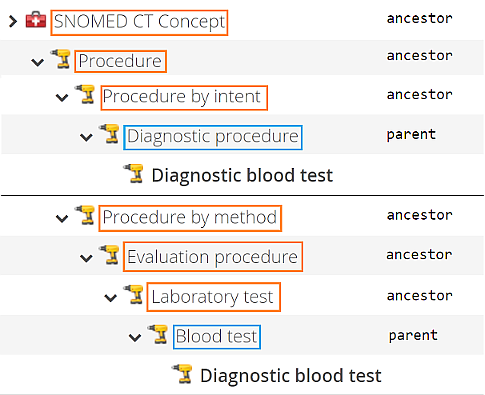
}GET /snomedct/MAIN/concepts/425758004 // Diagnostic blood test
{
[...]
"ancestorIds": [
"-1", // Special value for taxonomy root
"15220000", // Laboratory test
"71388002", // Procedure
"108252007", // Laboratory procedure (not pictured below)
"128927009", // Procedure by method
"138875005", // SNOMED CT Concept
"362961001", // Procedure by intent
"386053000" // Evaluation procedure
],
"parentIds": [
"103693007", // Diagnostic procedure
"396550006" // Blood test
],
[...]
}GET /snomedct/MAIN/concepts/900000000000497000?expand=referenceSet() // CTV3 simple map
{
"id": "900000000000497000",
"active": true,
[...]
"referenceSet": {
"id": "900000000000497000",
"released": true,
"active": true,
"effectiveTime": "20020131",
"moduleId": "900000000000012004",
"iconId": "900000000000496009",
"type": "SIMPLE_MAP", // Reference set type
"referencedComponentType": "concept", // Referenced component type
"mapTargetComponentType": "__UNKNOWN__" // Map target component type
// (applicable to map type reference sets only)
},
[...]
}GET /snomedct/MAIN/concepts/900000000000497000?expand=referenceSet(expand(members()))
{
"id": "900000000000497000",
[...]
"referenceSet": {
[...]
"type": "SIMPLE_MAP",
"referencedComponentType": "concept",
"mapTargetComponentType": "__UNKNOWN__",
"members": {
"items": [
{
"id": "00000193-e889-4d3f-b07f-e0f45eb77940",
"released": true,
"active": true,
"effectiveTime": "20190131",
"moduleId": "900000000000207008",
"iconId": "776792002",
"referencedComponent": {
"id": "776792002"
},
"refsetId": "900000000000497000", // Reference set ID matches the identifier concept's ID
// for all members of the reference set
"referencedComponentId": "776792002",
"mapTarget": "XV8E7"
},
[...]
],
"searchAfter": "AoE_BTAwMDcyYWIzLWM5NDgtNTVhYy04MTBkLTlhOGNhMmU5YjQ5Yg==",
"limit": 50,
"total": 481508
}
},
}GET /snomedct/MAIN/2011-07-31/concepts/86299006?expand=preferredDescriptions()
{
"id": "86299006", // Concept SCTID
[...]
"preferredDescriptions": {
"items": [
{
"id": "828532012", // Description SCTID
"term": "Tetralogy of Fallot (disorder)", // Description term
"concept": {
"id": "86299006"
},
"type": {
"id": "900000000000003001"
},
"typeId": "900000000000003001", // Type: Fully Specified Name
"conceptId": "86299006", // "conceptId" matches the returned concept's SCTID
"acceptability": {
"900000000000509007": "PREFERRED", // Acceptability in reference set "US English"
"900000000000508004": "PREFERRED" // Acceptability in reference set "GB English"
}
},
{
"id": "143123019",
"term": "Tetralogy of Fallot",
"concept": {
"id": "86299006"
},
"type": {
"id": "900000000000013009"
},
"typeId": "900000000000013009", // Type: Synonym
"conceptId": "86299006",
"acceptability": {
"900000000000509007": "PREFERRED",
"900000000000508004": "PREFERRED"
}
}
],
"limit": 2,
"total": 2
},
[...]
}GET /snomedct/MAIN/concepts/103981000119101?expand=preferredDescriptions(),semanticTags()
{
"id": "103981000119101",
"released": true,
"active": true,
"effectiveTime": "20200131",
"preferredDescriptions": {
"items": [
{
"id": "3781804016",
"term": "Proliferative retinopathy following surgery due to diabetes mellitus (disorder)",
[...]
},
[...]
]
}
[...]
"semanticTags": [ "disorder" ], // Extracted from the Fully Specified Name; see term above
[...]
}GET /snomedct/MAIN/concepts/99999003?expand=inactivationProperties()
{
"id": "99999003",
"active": false,
"effectiveTime": "20090731",
[...]
"inactivationProperties": {
"inactivationIndicator": {
"id": "900000000000487009"
},
"associationTargets": [
{
"referenceSet": {
"id": "900000000000524003"
},
"targetComponent": {
"id": "416516009"
},
"referenceSetId": "900000000000524003", // MOVED TO association reference set
"targetComponentId": "416516009" // Extension Namespace 1000009
}
],
"inactivationIndicatorId": "900000000000487009" // Moved elsewhere
},
[...]
}GET /snomedct/MAIN/concepts/99999003?expand=members()
{
"id": "99999003",
[...]
"members": {
"items": [
{
"id": "f2b12ff9-794a-5a05-8027-88f0492f3766",
"released": true,
"active": true,
"effectiveTime": "20020131",
"moduleId": "900000000000207008",
"iconId": "99999003",
"referencedComponent": {
"id": "99999003"
},
"refsetId": "900000000000497000", // CTV3 simple map
"referencedComponentId": "99999003", // all referencedComponentIds match the concept's SCTID
"mapTarget": "XUPhG" // additional properties are displayed depending on the
// reference set type
},
{
"id": "5e9787df-11af-54ed-ae92-0ea3bc83f2ac",
"released": true,
"active": true,
"effectiveTime": "20090731",
"moduleId": "900000000000207008",
"iconId": "99999003",
"referencedComponent": {
"id": "99999003"
},
"refsetId": "900000000000524003", // MOVED TO association reference set
"referencedComponentId": "99999003",
"targetComponentId": "416516009" // Extension Namespace 1000009
},
{
"id": "9ffd949a-27d0-5811-ad48-47ff43e1bded",
"released": true,
"active": true,
"effectiveTime": "20090731",
"moduleId": "900000000000207008",
"iconId": "99999003",
"referencedComponent": {
"id": "99999003"
},
"refsetId": "900000000000489007", // Concept inactivation indicator reference set
"referencedComponentId": "99999003",
"valueId": "900000000000487009" // Moved elsewhere
}
],
"limit": 3,
"total": 3
},
[...]
}GET /snomedct/MAIN/concepts/99999003?expand=members(active:true, refSetType:["ASSOCIATION","ATTRIBUTE_VALUE"])
{
"id": "99999003",
[...]
"members": {
[
{
"id": "5e9787df-11af-54ed-ae92-0ea3bc83f2ac",
"released": true,
"active": true,
"effectiveTime": "20090731",
"moduleId": "900000000000207008",
"iconId": "99999003",
"referencedComponent": {
"id": "99999003"
},
"refsetId": "900000000000524003", // MOVED TO association reference set
"referencedComponentId": "99999003",
"targetComponentId": "416516009" // Extension Namespace 1000009
},
{
"id": "9ffd949a-27d0-5811-ad48-47ff43e1bded",
"released": true,
"active": true,
"effectiveTime": "20090731",
"moduleId": "900000000000207008",
"iconId": "99999003",
"referencedComponent": {
"id": "99999003"
},
"refsetId": "900000000000489007", // Concept inactivation indicator reference set
"referencedComponentId": "99999003",
"valueId": "900000000000487009" // Moved elsewhere
}
],
"limit": 2,
"total": 2
},
[...]
}GET /snomedct/MAIN/concepts/138875005?expand=module()
{
"id": "138875005",
"active": true,
[...]
// The moduleId of the requested concept
"moduleId": "900000000000207008",
"module": { // Expanded module concept resource
"id": "900000000000207008", // SCTID matches 138875005's moduleId
"released": true,
"active": true,
"effectiveTime": "20020131",
// The moduleId of the module concept
"moduleId": "900000000000012004",
"iconId": "900000000000445007",
"definitionStatus": {
"id": "900000000000074008"
},
"subclassDefinitionStatus": "NON_DISJOINT_SUBCLASSES",
"ancestorIds": [...],
[...]
"definitionStatusId": "900000000000074008"
},
[...]
"definitionStatusId": "900000000000074008"
}GET /snomedct/MAIN/concepts/138875005?expand=definitionStatus()
{
"id": "138875005",
"active": true,
// The definitionStatusId of the requested concept
"definitionStatusId": "900000000000074008",
"definitionStatus": { // Expanded definition status concept resource
"id": "900000000000074008", // SCTID matches 138875005's definitionStatusId
"active": true,
"effectiveTime": "20020131",
[...]
// The definitionStatusId of the definition status concept
"definitionStatusId": "900000000000074008"
},
[...]
}GET /codesystems/SNOMEDCT-UK-CL
{
"id": "SNOMEDCT-UK-CL",
"title": "SNOMED CT UK Clinical Extension",
[...]
"settings": {
"languages": [
{
"languageTag": "en", // the language tag
"languageRefSetIds": [ // the corresponding language reference sets, in order of preference
"900000000000509007",
"900000000000508004",
"999001261000000100",
"999000691000001104"
]
},
{
"languageTag": "en-us",
"languageRefSetIds": [
"900000000000509007"
]
},
{
"languageTag": "en-gb",
"languageRefSetIds": [
"900000000000508004",
"999001261000000100",
"999000691000001104"
]
},
{
"languageTag": "en-nhs-pharmacy",
"languageRefSetIds": [
"999000691000001104"
]
},
{
"languageTag": "en-nhs-clinical",
"languageRefSetIds": [
"999001261000000100"
]
}
],
[...]
},
[...]
}GET /snomedct/MAIN/concepts/703247007?expand=pt()
// Accept-Language: en-US
{
"id": "703247007",
[...]
"pt": {
"id": "3007370016",
"term": "Color",
[...]
"conceptId": "703247007", // conceptId matches the concept's SCTID
"acceptability": {
// Use of "Color" is preferred in the US English language reference set,
// but not acceptable in others
"900000000000509007": "PREFERRED"
}
},
[...]
}GET /snomedct/MAIN/concepts/703247007?expand=pt()
// Accept-Language: en-x-900000000000508004
{
"id": "703247007",
[...]
"pt": {
"id": "3007469016",
"term": "Colour",
[...]
"conceptId": "703247007",
"acceptability": {
// Use of "Colour" is preferred in the GB English language reference set,
// but not acceptable in others
"900000000000508004": "PREFERRED"
}
},
[...]
}GET /snomedct/MAIN/concepts/86299006?expand=descriptions(active: true, sort: "term.exact:asc")
{
"id": "86299006",
[...]
"descriptions": {
"items": [
{
"id": "1235125018",
"released": true,
"active": true,
"effectiveTime": "20070731",
"moduleId": "900000000000207008",
"iconId": "900000000000013009",
"term": "Fallot's tetralogy", // Descriptions are sorted by term (case insensitive)
"semanticTag": "",
"languageCode": "en",
"caseSignificance": {
"id": "900000000000017005"
},
"concept": {
"id": "86299006"
},
"type": {
"id": "900000000000013009"
},
"typeId": "900000000000013009", // Synonym
"conceptId": "86299006", // conceptId property matches the concept's SCTID
"caseSignificanceId": "900000000000017005",
"acceptability": {
"900000000000509007": "ACCEPTABLE",
"900000000000508004": "ACCEPTABLE"
}
},
{
"id": "143125014",
"active": true,
"term": "Subpulmonic stenosis, ventricular septal defect, overriding aorta, AND right ventricular hypertrophy",
[...]
},
{
"id": "143123019",
"active": true,
"term": "Tetralogy of Fallot",
[...]
},
{
"id": "828532012",
"active": true,
"term": "Tetralogy of Fallot (disorder)",
"typeId": "900000000000003001", // Fully Specified Name
[...]
},
{
"id": "1235124019",
"active": true,
"term": "TOF - Tetralogy of Fallot",
[...]
}
],
"limit": 5,
"total": 5
},
[...]
}GET /snomedct/MAIN/concepts/404684003?expand=relationships(active: true)
{
"id": "404684003", // Clinical finding
"active": true,
[...]
"relationships": {
"items": [
{
"id": "2472459022",
"released": true,
"active": true,
"effectiveTime": "20040131",
"moduleId": "900000000000207008",
"iconId": "116680003",
"destinationNegated": false,
"relationshipGroup": 0,
"unionGroup": 0,
"characteristicType": {
"id": "900000000000011006"
},
"modifier": {
"id": "900000000000451002"
},
"source": {
"id": "404684003"
},
"type": {
"id": "116680003"
},
"destination": {
"id": "138875005"
},
"typeId": "116680003",
"modifierId": "900000000000451002",
"sourceId": "404684003", // sourceId property matches concept's SCTID
"destinationId": "138875005",
"characteristicTypeId": "900000000000011006"
}
],
"limit": 1,
"total": 1
},
[...]
}GET /snomedct/MAIN/concepts/138875005?expand=descendants(direct: true)
{
"id": "138875005", // SNOMED CT Concept
"active": true,
[...]
"descendants": {
"items": [
{
"id": "105590001", // Substance
"released": true,
"active": true,
"effectiveTime": "20020131",
"moduleId": "900000000000207008",
"iconId": "substance",
"definitionStatus": {
"id": "900000000000074008"
},
"subclassDefinitionStatus": "NON_DISJOINT_SUBCLASSES",
"ancestorIds": [
"-1"
],
"parentIds": [
"138875005" // parentIds contains SNOMED CT Concept's SCTID, meaning this concept
// is a direct (inferred) descendant of it
],
"statedAncestorIds": [
"-1"
],
"statedParentIds": [
"138875005"
],
"definitionStatusId": "900000000000074008"
},
[...]
],
"limit": 50,
"total": 19 // Total number of descendants
},
[...]
}GET /snomedct/MAIN/2019-07-31/concepts/138875005GET /snomedct/MAIN/2019-07-31/concepts/138875005?field=xyz
{
"status": 400,
"code": 0,
"message": "Unrecognized concept model property '[xyz]'.",
"developerMessage": "Supported properties are '[active, activeMemberOf, ancestors, ...]'.",
"errorCode": 0,
"statusCode": 400
}GET /snomedct/MAIN/2019-07-31/concepts/138875005?field=id,active,score
{
"id": "138875005",
"active": true
// score was not calculated, and so is not present
}GET /snomedct/MAIN/2019-07-31/concepts/138875005?expand=fsn()
// Accept-Language: hu-HU
{
"status": 400,
"code": 0,
"message": "Don't know how to convert extended locale [hu-hu] to a language reference set identifier.",
"developerMessage": "Input representation syntax or validation errors. Check input values.",
"errorCode": 0,
"statusCode": 400
}GET /snomedct/SNOMEDCT/2021-01-31/concepts
{
"items": [
{
"id": "100000000", // Each item represents a concept resource
"released": true,
"active": false,
"effectiveTime": "20090731",
"moduleId": "900000000000207008",
"iconId": "138875005",
"definitionStatus": {
"id": "900000000000074008"
},
"subclassDefinitionStatus": "NON_DISJOINT_SUBCLASSES",
"ancestorIds": [],
"parentIds": [
"-1"
],
"statedAncestorIds": [],
"statedParentIds": [
"-1"
],
"definitionStatusId": "900000000000074008"
},
[...] // at most 50 items are returned when no limit is specified
],
"searchAfter": "AoEpMTAwMDQyMDAz", // key can be used for paged results
"limit": 50, // the limit given in the original request
// (or the default limit if not specified)
"total": 481509 // the total number of concept matches
}GET /snomedct/SNOMEDCT/2021-01-31/concepts?ecl=<<404684003|Clinical finding|:363698007|Finding site|=40238009|Hand joint structure|
{
"items": [
[...]
{
"id": "129157005",
"active": true,
[...]
"pt": {
"id": "2664900016",
"term": "Traumatic dislocation of joint of hand", // Concept match based on ECL expression
[...]
},
[...]
},
[...]
],
"searchAfter": "AoEpNDQ4NDUzMDA0",
"limit": 50,
"total": 58
}Search term → Term of matched description
----------------- ---------------------------
"Ångström" "angstrom" (case insensitive, ASCII-folding)
"sys blo pre" "Systolic blood pressure" (prefix of each word, matching order)
"broken arm" "Fracture of arm" (synonym filter, ignored stopwords)
"greenstick frac" "Greenstick fracture" (prefix match for final query keyword,
exact match for all others)GET /snomedct/SNOMEDCT/2021-01-31/concepts?parent=138875005&field=id
{
"items": [
// Inferred direct descendants of 138875005|Snomed CT Concept|
{ "id": "105590001" }, // Substance
{ "id": "123037004" }, // Body structure
{ "id": "123038009" }, // Specimen
[...]
],
"searchAfter": "AoEyOTAwMDAwMDAwMDAwNDQxMDAz",
"limit": 50,
"total": 19 // 19 top-level concepts returned in total
}GET /snomedct/SNOMEDCT-UK-CL/concepts?namespaceConceptId=370138007&field=id
{
"items": [
// Concept IDs with a namespace identifier of "1000001", corresponding to
// namespace concept 370138007|Extension Namespace {1000001}|
{
"id": "999000011000001104" // 99900001>>1000001<<104
},
[...]
],
"searchAfter": "AoEyOTk5MDAwODcxMDAwMDAxMTAy",
"limit": 50,
"total": 4
}GET /snomedct/SNOMEDCT/2021-01-31/concepts?effectiveTime=20170131&field=id,effectiveTime
{
"items": [
{
"id": "10151000132103",
"effectiveTime": "20170131" // Concept effective time matches query parameter
},
{
"id": "10231000132102",
"effectiveTime": "20170131"
},
[...]
],
"searchAfter": "AoEwMTA3NTQ3MTAwMDExOTEwNw==",
"limit": 50,
"total": 5580 // Total number of concepts with effective time 2017-01-31
}GET /snomedct/SNOMEDCT/2021-01-31/concepts?effectiveTime=20170131&field=id,effectiveTime
{
"items": [
{
"id": "10151000132103",
"effectiveTime": "20170131"
},
{
"id": "10231000132102",
"effectiveTime": "20170131"
},
[...]
],
// Key to use in the request for the second page
"searchAfter": "AoEwMTA3NTQ3MTAwMDExOTEwNw==",
"limit": 50,
"total": 5580
}
GET /snomedct/SNOMEDCT/2021-01-31/concepts?effectiveTime=20170131&field=id,effectiveTime&searchAfter=AoEwMTA3NTQ3MTAwMDExOTEwNw==
{
"items": [
// List continues from the last item of the previous request
// (but the item itself is not included)
{
"id": "1075481000119105",
"effectiveTime": "20170131"
},
{
"id": "10759271000119104",
"effectiveTime": "20170131"
},
[...]
],
// Different key returned for the third page
"searchAfter": "AoEwMTA4MTgxMTAwMDExOTEwNw==",
"limit": 50,
"total": 5580
}POST /snomedct/SNOMEDCT/2021-01-31/concepts/search
// Request body
{
// Query parameters allowing multiple values must be passed as arrays
"expand": [ "pt()" ],
"field": [ "id", "preferredDescriptions" ],
"limit": 100,
"active": true,
"module": [ "900000000000012004" ]
}
// Response
{
"items": [
{
"id": "1003316002",
"moduleId": "900000000000012004",
"pt": {
"id": "4167978019",
"term": "Extension Namespace 1000256",
[...]
}
},
{
"id": "1003317006",
"moduleId": "900000000000012004",
"pt": {
"id": "4167981012",
"term": "Extension Namespace 1000257",
[...]
}
}
],
"searchAfter": "AoEqMTAwMzMxNzAwNg==",
"limit": 2,
"total": 1802
}// Create a concept on the working branch of code system SNOMEDCT-B2I
POST /snomedct/SNOMEDCT-B2I/concepts
// Request body
{
"active": true,
"moduleId": "636635721000154103", // SNOMED CT B2i extension module
"namespaceId": "1000154", // B2i Healthcare's namespace identifier
"definitionStatusId": "900000000000074008", // Primitive
"descriptions": [
// Create mandatory FSN and PT
{
"active": true,
// "moduleId", "namespaceId" will be set from the concept
// "id" will be generated for the description
// "conceptId" will be automatically populated with the new concept's SCTID
"typeId": "900000000000003001", // Fully specified name
"term": "Example concept (disorder)",
"languageCode": "en",
"caseSignificanceId": "900000000000448009", // Case insensitive
"acceptability": {
/*
Acceptability map entries are keyed by language reference set ID.
Allowed values are "PREFERRED" and "ACCEPTABLE".
*/
"900000000000509007": "PREFERRED" // US English
}
},
{
"active": true,
"typeId": "900000000000013009", // Synonym
"term": "Example concept",
"languageCode": "en",
"caseSignificanceId": "900000000000448009", // Case insensitive
"acceptability": {
"900000000000509007": "PREFERRED" // US English
}
}
],
"relationships": [
/*
Including relationships on a new concept request is optional.
However, when no inferred IS A relationship is created, the concept will not
be visible in the inferred hierarchy (and not show up in eg. ECL evaluations)
until a classification is run on the branch, and suggested changes are saved.
*/
{
"active": true,
// "moduleId", "namespaceId" will be set from the concept
// "id" will be generated for the relationship
// "sourceId" will be automatically populated with the new concept's SCTID
"typeId": "116680003", // IS A
"destinationId": "64572001", // Disease
"destinationNegated": false,
"relationshipGroup": 0,
"unionGroup": 0,
"characteristicTypeId": "900000000000011006", // Inferred relationship
"modifierId": "900000000000451002" // Some (existential restriction)
}
],
"members": [
{
// "id" is an UUID, will be automatically generated when not given
"active": true,
// "moduleId" needs to be set for reference set members; it is not propagated
"moduleId": "636635721000154103",
// "referencedComponentId" will be automatically populated with the new concept's SCTID
"refsetId": "733073007",
/*
Additional properties of the reference set should be added here. For an OWL
axiom reference set member, the property to the reference set type is called
"owlExpression".
At the moment we can not create an OWL axiom member for concepts that do not include
a concept ID in advance.
*/
"owlExpression": "SubClassOf(:<conceptId> :64572001)"
}
],
"commitComment": "Create new example concept"
}
// Response: 201 Created
// Location: /snomedct/SNOMEDCT-B2I/concepts/<SCTID of created concept>PUT /snomed-ct/v3/SNOMEDCT/concepts/69949008
// Request body
{
"active": false,
"inactivationProperties": {
"inactivationIndicatorId": "900000000000482003", // Duplicate
"associationTargets": [
{
"referenceSetId": "900000000000527005", // SAME AS association reference set
"targetComponentId": "273999003" // Neuroplasty
}
]
},
"commitComment": "Inactivate duplicate concept"
}
// Response: 204 No ContentPUT /snomed-ct/v3/SNOMEDCT/concepts/69949008
// Request body
{
"active": true,
"commitComment": "Reactivate concept"
}GET /snomed-ct/v3/SNOMEDCT/concepts/69949008
{
"id": "69949008",
"active": true,
[...]
"inactivationProperties": {
"associationTargets": []
},
[...]
}
// Response: 204 No ContentDELETE /snomedct/SNOMEDCT/2021-01-31/concepts/138875005
{
"status": 409,
"code": 0,
"message": "'concept' '138875005' cannot be deleted.",
"developerMessage": "'concept' '138875005' cannot be deleted.",
"errorCode": 0,
"statusCode": 409
}